
Exponential distribution
|
Probability density function  | |||
|
Cumulative distribution function  | |||
| Parameters | rate, or inverse scale | ||
|---|---|---|---|
| Support | |||
| CDF | |||
| Quantile | |||
| Mean | |||
| Median | |||
| Mode | |||
| Variance | |||
| Skewness | |||
| Excess kurtosis | |||
| Entropy | |||
| MGF | |||
| CF | |||
| Fisher information | |||
| Kullback–Leibler divergence | |||
| Expected shortfall | |||
















In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the distance between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate; the distance parameter could be any meaningful mono-dimensional measure of the process, such as time between production errors, or length along a roll of fabric in the weaving manufacturing process.[1] It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless.[2] In addition to being used for the analysis of Poisson point processes it is found in various other contexts.[3]
The exponential distribution is not the same as the class of exponential families of distributions. This is a large class of probability distributions that includes the exponential distribution as one of its members, but also includes many other distributions, like the normal, binomial, gamma, and Poisson distributions.[3]
Definitions
Probability density function
The probability density function (pdf) of an exponential distribution is

Here λ > 0 is the parameter of the distribution, often called the rate parameter. The distribution is supported on the interval [0, ∞). If a random variable X has this distribution, we write X ~ Exp(λ).
The exponential distribution exhibits infinite divisibility.
Cumulative distribution function
The cumulative distribution function is given by

Alternative parametrization
The exponential distribution is sometimes parametrized in terms of the scale parameter β = 1/λ, which is also the mean:

Properties
Mean, variance, moments, and median


The mean or expected value of an exponentially distributed random variable X with rate parameter λ is given by
![{\displaystyle \operatorname {E} [X]={\frac {1}{\lambda }}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f9efa3ce3c964c59532609b3d6b8f01ce88f6221)
In light of the examples given below, this makes sense; a person who receives an average of two telephone calls per hour can expect that the time between consecutive calls will be 0.5 hour, or 30 minutes.
The variance of X is given by so the standard deviation is equal to the mean.
![{\displaystyle \operatorname {Var} [X]={\frac {1}{\lambda ^{2}}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3c450db5013b1cfdaf5ea71106c9d13834e02d61)
The moments of X, for are given by

![{\displaystyle \operatorname {E} \left[X^{n}\right]={\frac {n!}{\lambda ^{n}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5f5d3a82fbcff5a294e5360fb05b1e5f2166ec09)
The central moments of X, for are given by where !n is the subfactorial of n

The median of X is given by where ln refers to the natural logarithm. Thus the absolute difference between the mean and median is
![{\displaystyle \operatorname {m} [X]={\frac {\ln(2)}{\lambda }}<\operatorname {E} [X],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7f19becbfbc702d8c33a9698c779384fe3f4dca1)
![{\displaystyle \left|\operatorname {E} \left[X\right]-\operatorname {m} \left[X\right]\right|={\frac {1-\ln(2)}{\lambda }}<{\frac {1}{\lambda }}=\operatorname {\sigma } [X],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e48a50d7c835e2c16f59682fe49712aa41a54d8a)
in accordance with the median-mean inequality.
Memorylessness property of exponential random variable
An exponentially distributed random variable T obeys the relation

This can be seen by considering the complementary cumulative distribution function:
![{\displaystyle {\begin{aligned}\Pr \left(T>s+t\mid T>s\right)&={\frac {\Pr \left(T>s+t\cap T>s\right)}{\Pr \left(T>s\right)}}\\[4pt]&={\frac {\Pr \left(T>s+t\right)}{\Pr \left(T>s\right)}}\\[4pt]&={\frac {e^{-\lambda (s+t)}}{e^{-\lambda s}}}\\[4pt]&=e^{-\lambda t}\\[4pt]&=\Pr(T>t).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/126da1213459cde98ae372eae857a18183675f5a)
When T is interpreted as the waiting time for an event to occur relative to some initial time, this relation implies that, if T is conditioned on a failure to observe the event over some initial period of time s, the distribution of the remaining waiting time is the same as the original unconditional distribution. For example, if an event has not occurred after 30 seconds, the conditional probability that occurrence will take at least 10 more seconds is equal to the unconditional probability of observing the event more than 10 seconds after the initial time.
The exponential distribution and the geometric distribution are the only memoryless probability distributions.
The exponential distribution is consequently also necessarily the only continuous probability distribution that has a constant failure rate.
Quantiles

The quantile function (inverse cumulative distribution function) for Exp(λ) is

The quartiles are therefore:
- first quartile: ln(4/3)/λ
- median: ln(2)/λ
- third quartile: ln(4)/λ
And as a consequence the interquartile range is ln(3)/λ.
Conditional Value at Risk (Expected Shortfall)
The conditional value at risk (CVaR) also known as the expected shortfall or superquantile for Exp(λ) is derived as follows:[4]
![{\displaystyle {\begin{aligned}{\bar {q}}_{\alpha }(X)&={\frac {1}{1-\alpha }}\int _{\alpha }^{1}q_{p}(X)dp\\&={\frac {1}{(1-\alpha )}}\int _{\alpha }^{1}{\frac {-\ln(1-p)}{\lambda }}dp\\&={\frac {-1}{\lambda (1-\alpha )}}\int _{1-\alpha }^{0}-\ln(y)dy\\&={\frac {-1}{\lambda (1-\alpha )}}\int _{0}^{1-\alpha }\ln(y)dy\\&={\frac {-1}{\lambda (1-\alpha )}}[(1-\alpha )\ln(1-\alpha )-(1-\alpha )]\\&={\frac {-\ln(1-\alpha )+1}{\lambda }}\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8cb6c9508565c42978ca1153dc0f6bfd0199a45c)
Buffered Probability of Exceedance (bPOE)
The buffered probability of exceedance is one minus the probability level at which the CVaR equals the threshold . It is derived as follows:[4]


Kullback–Leibler divergence
The directed Kullback–Leibler divergence in nats of ("approximating" distribution) from ('true' distribution) is given by



Maximum entropy distribution
Among all continuous probability distributions with support [0, ∞) and mean μ, the exponential distribution with λ = 1/μ has the largest differential entropy. In other words, it is the maximum entropy probability distribution for a random variate X which is greater than or equal to zero and for which E[X] is fixed.[5]
Distribution of the minimum of exponential random variables
Let X1, ..., Xn be independent exponentially distributed random variables with rate parameters λ1, ..., λn. Then is also exponentially distributed, with parameter


This can be seen by considering the complementary cumulative distribution function:

The index of the variable which achieves the minimum is distributed according to the categorical distribution

A proof can be seen by letting . Then,


Note that is not exponentially distributed, if X1, ..., Xn do not all have parameter 0.[6]

Joint moments of i.i.d. exponential order statistics
Let be independent and identically distributed exponential random variables with rate parameter λ. Let denote the corresponding order statistics. For , the joint moment of the order statistics and is given by




![{\displaystyle \operatorname {E} \left[X_{(i)}X_{(j)}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7d350557a602c2566c092558fff0aefb0049c7c9)


![{\displaystyle {\begin{aligned}\operatorname {E} \left[X_{(i)}X_{(j)}\right]&=\sum _{k=0}^{j-1}{\frac {1}{(n-k)\lambda }}\operatorname {E} \left[X_{(i)}\right]+\operatorname {E} \left[X_{(i)}^{2}\right]\\&=\sum _{k=0}^{j-1}{\frac {1}{(n-k)\lambda }}\sum _{k=0}^{i-1}{\frac {1}{(n-k)\lambda }}+\sum _{k=0}^{i-1}{\frac {1}{((n-k)\lambda )^{2}}}+\left(\sum _{k=0}^{i-1}{\frac {1}{(n-k)\lambda }}\right)^{2}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0135f144a56c4b7565f7faa61cc3abb42afe9c0d)
This can be seen by invoking the law of total expectation and the memoryless property:
![{\displaystyle {\begin{aligned}\operatorname {E} \left[X_{(i)}X_{(j)}\right]&=\int _{0}^{\infty }\operatorname {E} \left[X_{(i)}X_{(j)}\mid X_{(i)}=x\right]f_{X_{(i)}}(x)\,dx\\&=\int _{x=0}^{\infty }x\operatorname {E} \left[X_{(j)}\mid X_{(j)}\geq x\right]f_{X_{(i)}}(x)\,dx&&\left({\textrm {since}}~X_{(i)}=x\implies X_{(j)}\geq x\right)\\&=\int _{x=0}^{\infty }x\left[\operatorname {E} \left[X_{(j)}\right]+x\right]f_{X_{(i)}}(x)\,dx&&\left({\text{by the memoryless property}}\right)\\&=\sum _{k=0}^{j-1}{\frac {1}{(n-k)\lambda }}\operatorname {E} \left[X_{(i)}\right]+\operatorname {E} \left[X_{(i)}^{2}\right].\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be5949313f3639a86ac81484ac8ca7f4f9edb4d4)
The first equation follows from the law of total expectation. The second equation exploits the fact that once we condition on , it must follow that . The third equation relies on the memoryless property to replace with .


![{\displaystyle \operatorname {E} \left[X_{(j)}\mid X_{(j)}\geq x\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/00169b33907d379235fd4561c63c13d4c51a619a)
![{\displaystyle \operatorname {E} \left[X_{(j)}\right]+x}](https://wikimedia.org/api/rest_v1/media/math/render/svg/775aa6cfd6c5d2b1e4b70ce3108a17f93f7b0224)
Sum of two independent exponential random variables
The probability distribution function (PDF) of a sum of two independent random variables is the convolution of their individual PDFs. If and are independent exponential random variables with respective rate parameters and then the probability density of is given by The entropy of this distribution is available in closed form: assuming (without loss of generality), then where is the Euler-Mascheroni constant, and is the digamma function.[7]





![{\displaystyle {\begin{aligned}f_{Z}(z)&=\int _{-\infty }^{\infty }f_{X_{1}}(x_{1})f_{X_{2}}(z-x_{1})\,dx_{1}\\&=\int _{0}^{z}\lambda _{1}e^{-\lambda _{1}x_{1}}\lambda _{2}e^{-\lambda _{2}(z-x_{1})}\,dx_{1}\\&=\lambda _{1}\lambda _{2}e^{-\lambda _{2}z}\int _{0}^{z}e^{(\lambda _{2}-\lambda _{1})x_{1}}\,dx_{1}\\&={\begin{cases}{\dfrac {\lambda _{1}\lambda _{2}}{\lambda _{2}-\lambda _{1}}}\left(e^{-\lambda _{1}z}-e^{-\lambda _{2}z}\right)&{\text{ if }}\lambda _{1}\neq \lambda _{2}\\[4pt]\lambda ^{2}ze^{-\lambda z}&{\text{ if }}\lambda _{1}=\lambda _{2}=\lambda .\end{cases}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c2db15dda49fe8482485a68c9d7c9b1c1d46ee95)




In the case of equal rate parameters, the result is an Erlang distribution with shape 2 and parameter which in turn is a special case of gamma distribution.

The sum of n independent Exp(λ) exponential random variables is Gamma(n, λ) distributed.
Related distributions
- If X ~ Laplace(μ, β−1), then |X − μ| ~ Exp(β).[8]
- If X ~ Pareto(1, λ), then log(X) ~ Exp(λ).[8]
- If X ~ SkewLogistic(θ), then .
- If Xi ~ U(0, 1) then
- The exponential distribution is a limit of a scaled beta distribution:
- The exponential distribution is a special case of type 3 Pearson distribution.
- The exponential distribution is the special case of a Gamma distribution with shape parameter 1.[8]
- If X ~ Exp(λ) and Xi ~ Exp(λi) then:
- , closure under scaling by a positive factor.
- 1 + X ~ BenktanderWeibull(λ, 1), which reduces to a truncated exponential distribution.
- keX ~ Pareto(k, λ).[8]
- e−X ~ Beta(λ, 1).[8]
- 1/keX ~ PowerLaw(k, λ)
- , the Rayleigh distribution[8]
- , the Weibull distribution[8]
- [8]
- μ − β log(λX) ∼ Gumbel(μ, β).
- , a geometric distribution on 0,1,2,3,...
- , a geometric distribution on 1,2,3,4,...
- If also Y ~ Erlang(n, λ) or then
- If also λ ~ Gamma(k, θ) (shape, scale parametrisation) then the marginal distribution of X is Lomax(k, 1/θ), the gamma mixture
- λ1X1 − λ2Y2 ~ Laplace(0, 1).
- min{X1, ..., Xn} ~ Exp(λ1 + ... + λn).
- If also λi = λ then:
- If also Xi are independent, then:
- ~ U(0, 1)
- has probability density function . This can be used to obtain a confidence interval for .
- If also λ = 1:
- , the logistic distribution
- μ − σ log(X) ~ GEV(μ, σ, 0).
- Further if then (K-distribution)
- If also λ = 1/2 then X ∼ χ2
2; i.e., X has a chi-squared distribution with 2 degrees of freedom. Hence:
- If and ~ Poisson(X) then (geometric distribution)
- The Hoyt distribution can be obtained from exponential distribution and arcsine distribution
- The exponential distribution is a limit of the κ-exponential distribution in the case.
- Exponential distribution is a limit of the κ-Generalized Gamma distribution in the and cases:






























Other related distributions:
- Hyper-exponential distribution – the distribution whose density is a weighted sum of exponential densities.
- Hypoexponential distribution – the distribution of a general sum of exponential random variables.[8]
- exGaussian distribution – the sum of an exponential distribution and a normal distribution.
Statistical inference
Below, suppose random variable X is exponentially distributed with rate parameter λ, and are n independent samples from X, with sample mean .


Parameter estimation
The maximum likelihood estimator for λ is constructed as follows.
The likelihood function for λ, given an independent and identically distributed sample x = (x1, ..., xn) drawn from the variable, is:

where: is the sample mean.

The derivative of the likelihood function's logarithm is:
![{\displaystyle {\frac {d}{d\lambda }}\ln L(\lambda )={\frac {d}{d\lambda }}\left(n\ln \lambda -\lambda n{\overline {x}}\right)={\frac {n}{\lambda }}-n{\overline {x}}\ {\begin{cases}>0,&0<\lambda <{\frac {1}{\overline {x}}},\\[8pt]=0,&\lambda ={\frac {1}{\overline {x}}},\\[8pt]<0,&\lambda >{\frac {1}{\overline {x}}}.\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/65ec59bc9ccff1952291621e3eccc741ee1341a2)
Consequently, the maximum likelihood estimate for the rate parameter is:

This is not an unbiased estimator of although is an unbiased[10] MLE[11] estimator of and the distribution mean.


The bias of is equal to which yields the bias-corrected maximum likelihood estimator

![{\displaystyle B\equiv \operatorname {E} \left[\left({\widehat {\lambda }}_{\text{mle}}-\lambda \right)\right]={\frac {\lambda }{n-1}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6df9c9d7b6d1a8ffc31748e7cdf0cc750b442e4)

An approximate minimizer of mean squared error (see also: bias–variance tradeoff) can be found, assuming a sample size greater than two, with a correction factor to the MLE: This is derived from the mean and variance of the inverse-gamma distribution, .[12]


Fisher information
The Fisher information, denoted , for an estimator of the rate parameter is given as:


![{\displaystyle {\mathcal {I}}(\lambda )=\operatorname {E} \left[\left.\left({\frac {\partial }{\partial \lambda }}\log f(x;\lambda )\right)^{2}\right|\lambda \right]=\int \left({\frac {\partial }{\partial \lambda }}\log f(x;\lambda )\right)^{2}f(x;\lambda )\,dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2c70bd835b54bb1b7f344dbf1f04d170bd1d4852)
Plugging in the distribution and solving gives:

This determines the amount of information each independent sample of an exponential distribution carries about the unknown rate parameter .
Confidence intervals
An exact 100(1 − α)% confidence interval for the rate parameter of an exponential distribution is given by:[13]
which is also equal to
where χ2
p,v is the 100(p) percentile of the chi squared distribution with v degrees of freedom, n is the number of observations and x-bar is the sample average. A simple approximation to the exact interval endpoints can be derived using a normal approximation to the χ2
p,v distribution. This approximation gives the following values for a 95% confidence interval:



This approximation may be acceptable for samples containing at least 15 to 20 elements.[14]
Bayesian inference
The conjugate prior for the exponential distribution is the gamma distribution (of which the exponential distribution is a special case). The following parameterization of the gamma probability density function is useful:

The posterior distribution p can then be expressed in terms of the likelihood function defined above and a gamma prior:

Now the posterior density p has been specified up to a missing normalizing constant. Since it has the form of a gamma pdf, this can easily be filled in, and one obtains:

Here the hyperparameter α can be interpreted as the number of prior observations, and β as the sum of the prior observations. The posterior mean here is:

Occurrence and applications
Occurrence of events
The exponential distribution occurs naturally when describing the lengths of the inter-arrival times in a homogeneous Poisson process.
The exponential distribution may be viewed as a continuous counterpart of the geometric distribution, which describes the number of Bernoulli trials necessary for a discrete process to change state. In contrast, the exponential distribution describes the time for a continuous process to change state.
In real-world scenarios, the assumption of a constant rate (or probability per unit time) is rarely satisfied. For example, the rate of incoming phone calls differs according to the time of day. But if we focus on a time interval during which the rate is roughly constant, such as from 2 to 4 p.m. during work days, the exponential distribution can be used as a good approximate model for the time until the next phone call arrives. Similar caveats apply to the following examples which yield approximately exponentially distributed variables:
- The time until a radioactive particle decays, or the time between clicks of a Geiger counter
- The time between receiving one telephone call and the next
- The time until default (on payment to company debt holders) in reduced-form credit risk modeling
Exponential variables can also be used to model situations where certain events occur with a constant probability per unit length, such as the distance between mutations on a DNA strand, or between roadkills on a given road.
In queuing theory, the service times of agents in a system (e.g. how long it takes for a bank teller etc. to serve a customer) are often modeled as exponentially distributed variables. (The arrival of customers for instance is also modeled by the Poisson distribution if the arrivals are independent and distributed identically.) The length of a process that can be thought of as a sequence of several independent tasks follows the Erlang distribution (which is the distribution of the sum of several independent exponentially distributed variables). Reliability theory and reliability engineering also make extensive use of the exponential distribution. Because of the memoryless property of this distribution, it is well-suited to model the constant hazard rate portion of the bathtub curve used in reliability theory. It is also very convenient because it is so easy to add failure rates in a reliability model. The exponential distribution is however not appropriate to model the overall lifetime of organisms or technical devices, because the "failure rates" here are not constant: more failures occur for very young and for very old systems.
In physics, if you observe a gas at a fixed temperature and pressure in a uniform gravitational field, the heights of the various molecules also follow an approximate exponential distribution, known as the Barometric formula. This is a consequence of the entropy property mentioned below.
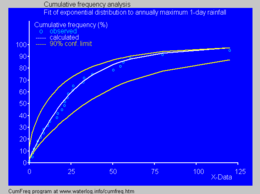
In hydrology, the exponential distribution is used to analyze extreme values of such variables as monthly and annual maximum values of daily rainfall and river discharge volumes.[16]
- The blue picture illustrates an example of fitting the exponential distribution to ranked annually maximum one-day rainfalls showing also the 90% confidence belt based on the binomial distribution. The rainfall data are represented by plotting positions as part of the cumulative frequency analysis.
In operating-rooms management, the distribution of surgery duration for a category of surgeries with no typical work-content (like in an emergency room, encompassing all types of surgeries).
Prediction
Having observed a sample of n data points from an unknown exponential distribution a common task is to use these samples to make predictions about future data from the same source. A common predictive distribution over future samples is the so-called plug-in distribution, formed by plugging a suitable estimate for the rate parameter λ into the exponential density function. A common choice of estimate is the one provided by the principle of maximum likelihood, and using this yields the predictive density over a future sample xn+1, conditioned on the observed samples x = (x1, ..., xn) given by

The Bayesian approach provides a predictive distribution which takes into account the uncertainty of the estimated parameter, although this may depend crucially on the choice of prior.
A predictive distribution free of the issues of choosing priors that arise under the subjective Bayesian approach is

which can be considered as
- a frequentist confidence distribution, obtained from the distribution of the pivotal quantity ;[17]
- a profile predictive likelihood, obtained by eliminating the parameter λ from the joint likelihood of xn+1 and λ by maximization;[18]
- an objective Bayesian predictive posterior distribution, obtained using the non-informative Jeffreys prior 1/λ;
- the Conditional Normalized Maximum Likelihood (CNML) predictive distribution, from information theoretic considerations.[19]

The accuracy of a predictive distribution may be measured using the distance or divergence between the true exponential distribution with rate parameter, λ0, and the predictive distribution based on the sample x. The Kullback–Leibler divergence is a commonly used, parameterisation free measure of the difference between two distributions. Letting Δ(λ0||p) denote the Kullback–Leibler divergence between an exponential with rate parameter λ0 and a predictive distribution p it can be shown that
![{\displaystyle {\begin{aligned}\operatorname {E} _{\lambda _{0}}\left[\Delta (\lambda _{0}\parallel p_{\rm {ML}})\right]&=\psi (n)+{\frac {1}{n-1}}-\log(n)\\\operatorname {E} _{\lambda _{0}}\left[\Delta (\lambda _{0}\parallel p_{\rm {CNML}})\right]&=\psi (n)+{\frac {1}{n}}-\log(n)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/02702bfd262096d01f27b67eab961ff7ccb512a9)
where the expectation is taken with respect to the exponential distribution with rate parameter λ0 ∈ (0, ∞), and ψ( · ) is the digamma function. It is clear that the CNML predictive distribution is strictly superior to the maximum likelihood plug-in distribution in terms of average Kullback–Leibler divergence for all sample sizes n > 0.
Random variate generation
A conceptually very simple method for generating exponential variates is based on inverse transform sampling: Given a random variate U drawn from the uniform distribution on the unit interval (0, 1), the variate

has an exponential distribution, where F−1 is the quantile function, defined by

Moreover, if U is uniform on (0, 1), then so is 1 − U. This means one can generate exponential variates as follows:

Other methods for generating exponential variates are discussed by Knuth[20] and Devroye.[21]
A fast method for generating a set of ready-ordered exponential variates without using a sorting routine is also available.[21]
See also
- Dead time – an application of exponential distribution to particle detector analysis.
- Laplace distribution, or the "double exponential distribution".
- Relationships among probability distributions
- Marshall–Olkin exponential distribution
References
- ^ "7.2: Exponential Distribution". Statistics LibreTexts. 2021-07-15. Retrieved 2024-10-11.
- ^ "Exponential distribution | mathematics | Britannica". www.britannica.com. Retrieved 2024-10-11.
- ^ a b Weisstein, Eric W. "Exponential Distribution". mathworld.wolfram.com. Retrieved 2024-10-11.
- ^ a b Norton, Matthew; Khokhlov, Valentyn; Uryasev, Stan (2019). "Calculating CVaR and bPOE for common probability distributions with application to portfolio optimization and density estimation" (PDF). Annals of Operations Research. 299 (1–2). Springer: 1281–1315. doi:10.1007/s10479-019-03373-1. Archived from the original (PDF) on 2023-03-31. Retrieved 2023-02-27.
- ^ Park, Sung Y.; Bera, Anil K. (2009). "Maximum entropy autoregressive conditional heteroskedasticity model" (PDF). Journal of Econometrics. 150 (2). Elsevier: 219–230. doi:10.1016/j.jeconom.2008.12.014. Archived from the original (PDF) on 2016-03-07. Retrieved 2011-06-02.
- ^ Michael, Lugo. "The expectation of the maximum of exponentials" (PDF). Archived from the original (PDF) on 20 December 2016. Retrieved 13 December 2016.
- ^ Eckford, Andrew W.; Thomas, Peter J. (2016). "Entropy of the sum of two independent, non-identically-distributed exponential random variables". arXiv:1609.02911 [cs.IT].
- ^ a b c d e f g h i Leemis, Lawrence M.; McQuestion, Jacquelyn T. (February 2008). "Univariate Distribution Relationships" (PDF). The American Statistician". 62 (1): 45-53.
- ^ Ibe, Oliver C. (2014). Fundamentals of Applied Probability and Random Processes (2nd ed.). Academic Press. p. 128. ISBN 9780128010358.
- ^ Richard Arnold Johnson; Dean W. Wichern (2007). Applied Multivariate Statistical Analysis. Pearson Prentice Hall. ISBN 978-0-13-187715-3. Retrieved 10 August 2012.
- ^ NIST/SEMATECH e-Handbook of Statistical Methods
- ^ Elfessi, Abdulaziz; Reineke, David M. (2001). "A Bayesian Look at Classical Estimation: The Exponential Distribution". Journal of Statistics Education. 9 (1). doi:10.1080/10691898.2001.11910648.
- ^ Ross, Sheldon M. (2009). Introduction to probability and statistics for engineers and scientists (4th ed.). Associated Press. p. 267. ISBN 978-0-12-370483-2.
- ^ Guerriero, V. (2012). "Power Law Distribution: Method of Multi-scale Inferential Statistics". Journal of Modern Mathematics Frontier. 1: 21–28.
- ^ "Cumfreq, a free computer program for cumulative frequency analysis".
- ^ Ritzema, H.P., ed. (1994). Frequency and Regression Analysis. Chapter 6 in: Drainage Principles and Applications, Publication 16, International Institute for Land Reclamation and Improvement (ILRI), Wageningen, The Netherlands. pp. 175–224. ISBN 90-70754-33-9.
- ^ Lawless, J. F.; Fredette, M. (2005). "Frequentist predictions intervals and predictive distributions". Biometrika. 92 (3): 529–542. doi:10.1093/biomet/92.3.529.
- ^ Bjornstad, J.F. (1990). "Predictive Likelihood: A Review". Statist. Sci. 5 (2): 242–254. doi:10.1214/ss/1177012175.
- ^ D. F. Schmidt and E. Makalic, "Universal Models for the Exponential Distribution", IEEE Transactions on Information Theory, Volume 55, Number 7, pp. 3087–3090, 2009 doi:10.1109/TIT.2009.2018331
- ^ Donald E. Knuth (1998). The Art of Computer Programming, volume 2: Seminumerical Algorithms, 3rd edn. Boston: Addison–Wesley. ISBN 0-201-89684-2. See section 3.4.1, p. 133.
- ^ a b Luc Devroye (1986). Non-Uniform Random Variate Generation. New York: Springer-Verlag. ISBN 0-387-96305-7. See chapter IX, section 2, pp. 392–401.
External links
- "Exponential distribution", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Online calculator of Exponential Distribution
| Authority control databases: National |
|---|